Обработка pdf файлов в ChatGPT
В данной статье я хочу рассказать как обработать папку с текстовыми PDF документами при помощи ChatGPT.
Время от времени у меня появляется задача обработать большое количество pdf-файлов содержащих нужную мне информацию. Для того чтобы обработать все документы, необходимо каждый PDF файл открыть прочитать и понять есть ли в файле нужная мне информация. Было бы здорово если бы я мог провести предварительную автоматическую обработку файлов и сохранить результат в текстовом файле, чтобы затем обработать только те файлы которые мне интересны.
К счастью современные технологии предоставляют такую возможность. Рассмотрим это задачу на примере папки на диске с резюме различных искателей я хочу вычленить из каждого документами фамилию имя отчество, должность и сколько лет опыта у каждого.
Сначала попробуем проверить возможно ли это на примере следующего запроса к chatgpt:
я хочу чтобы ты прочитал резюме кандидата и
вычленил профессиональные качества этого человека.
Меня интересует следующая информация: имя, профессия, сколько лет опыта, индустрия
Постарайся выбирать только факты представленные в документе с минимумом допущений.
Результат должен быть в json формате следующего вида
{"ФИО":"Иванов Иван Иванович", "профессия": "software injeneer", "годаОпыта": "10 лет", "индустрия": "геймдев"}
Если информации недостаточно просто оставь поле пустым.
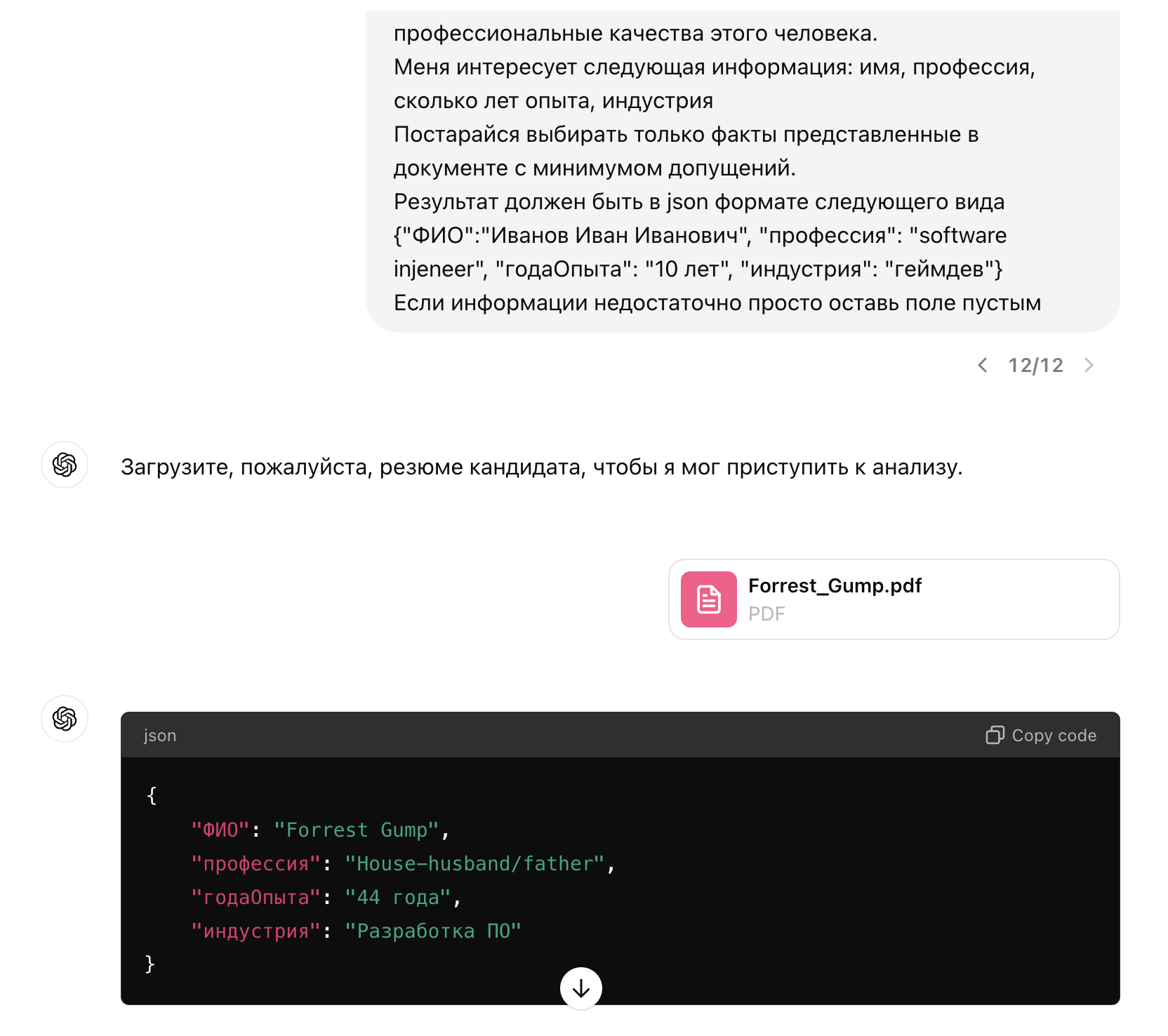
Как мы видим робот смог вычленить нужную мне информацию и вывести ее в нужном мне виде. Значит этот процесс можно автоматизировать.
Для начала на этой странице нужно создать ключи доступа к API chatgpt, чтобы обращаться к языковой модели программно:
После этого на этой странице следует оплатить стоимость API закинув любую сумму от 5 евро на счёт. Даже если у вас уже есть платная подписка к ChatGPT пользование API в нее не входит и оплачивается отдельно. Следует обратить внимание, что не все страны доступные для пользования API. России в частности в списке разрешённых стран нет.
Убедимся что у нас установлен nodejs и npm
# should be something like v20.11.1
node --version
# should be something like 10.8.2
npm --version
Для извлечения текста из pdf установим утилиту pdf2text
# ubuntu users
sudo apt-get install poppler-utils
# mac users
brew install poppler
pdftotext -h
# Copyright 2005-2024 The Poppler Developers - http://poppler.freedesktop.org
# Copyright 1996-2011, 2022 Glyph & Cog, LLC
Клонируем git репозиторий и устанавливаем зависимости.
git clone https://github.com/maxistar/pdf-analiser.git
cd pdf-analiser
# you can also use npm but pnpm is faster but you should install it first
pnpm install
В терминале экспортируем переменную окружения с нашим openai ключом.
export OPENAI_API_KEY="sk-xxxxx...
Запускаем командой npm start чтобы обработать тестовые pdf в папке data/cvs. После запуска результат обработки будет сохранен в файле data/output/files_yyyMMMddddhhmm.csv. Файл должен выглядить примерно вот так:
File Name,Size (bytes),name,title,experience,industry
Forrest Gump.pdf,155415,"Forrest Gump","house-husband/father","43 года","IT"
Forrest_Gump-1.pdf,155415,"Forrest Gump","House-husband/father","43 года",""
Forrest_Gump.pdf,155415,"Forrest Gump","","","Разработка ПО"
После того как мы убедились что все работает копируем наши файлы которые нужно обработать в папку data/cvs и запускаем обработку еще раз.
Мы обработали папку с PDF файлами содержащими CV соискателей и сохранили интересующие нас данные в csv файл. Следует понимать что языковые модели могут выдавать при одних и тех-же запросах разные результаты, поэтому для более предсказуемого результата можно обработать набор несколько раз и усреднить результат.
Подобным образом можно обработать любое количество документов любого типа. Указанный метод не бесплатный. Обработка сотни документов обходится примерно 2 евро. Однако обработка вручную такого количества документов может оказаться еще дороже.
разрешены только теги br, font, span, p, strong, u, p, blockquote, a, div, img - остальные будут безжалостно удаляться
комментарии: